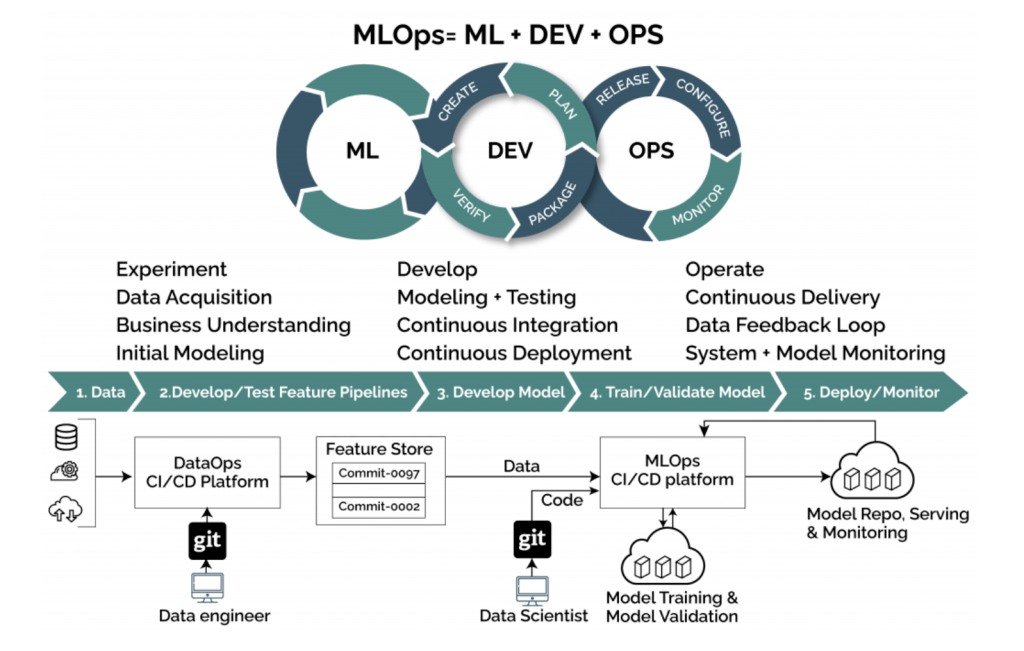
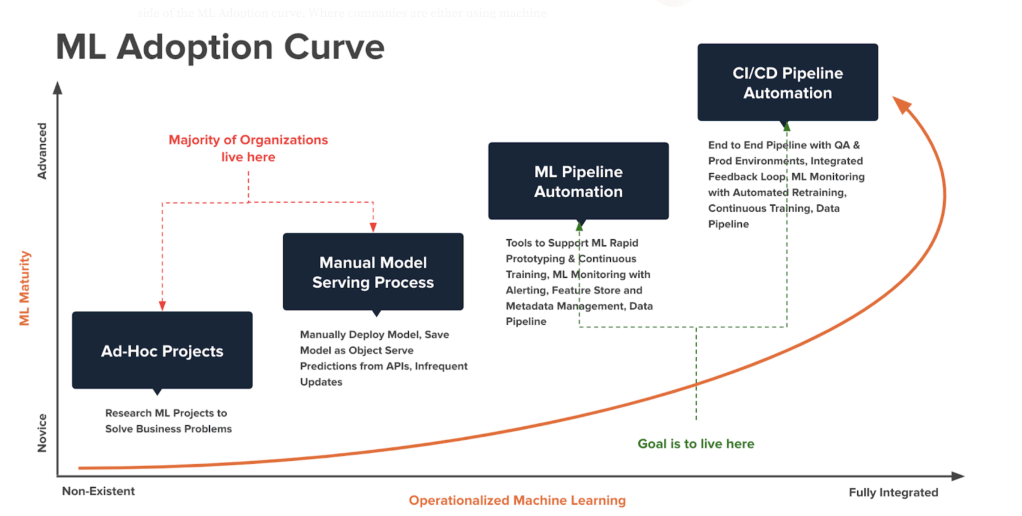
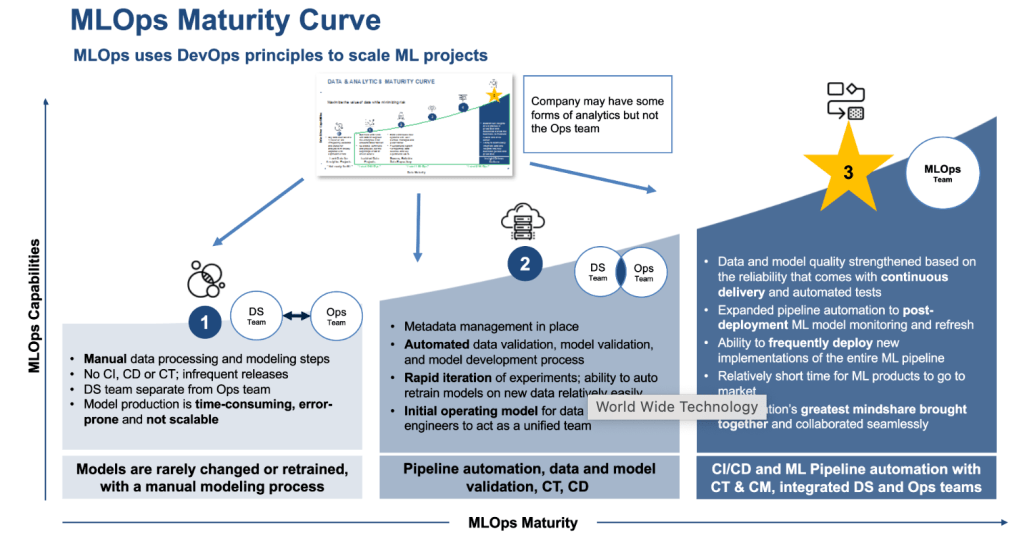
Integrated development environments aka IDEs can be a valuable tool for machine learning development, management, and deployment. They can help developers to write better code, debug code, visualize data, manage projects, and deploy models. But how does regular IDEs differ from the ones used for Machine learning and AI application development? IDEs for machine learning development and normal application development differ in a few key ways:
- Features: IDEs for machine learning development typically include features that are specifically designed for machine learning, such as:
- Built-in libraries and tools: IDEs for machine learning development typically have built-in libraries and tools that are specifically designed for machine learning tasks. This can save developers time and effort, as they don’t have to install and configure these libraries and tools themselves.
- Visualization tools: IDEs for machine learning development typically have visualization tools that can help developers to understand and debug machine learning models. This can be helpful for identifying patterns in the data and for understanding how the model works.
- Integration with machine learning frameworks: IDEs for machine learning development typically integrate with popular machine learning frameworks, such as TensorFlow, PyTorch, and scikit-learn. This makes it easier for developers to use these frameworks to build and train machine learning models.
- Integration with machine learning cloud platforms: Normal application IDEs may not have this focus, as they are not as reliant on cloud platforms.
- Community: IDEs for machine learning development tend to have a larger and more active community of users, which can be helpful for getting help and finding resources.
- Focus: IDEs for machine learning development tend to be more focused on machine learning, while IDEs for normal application development may be more focused on general-purpose programming.
Here are some of the most popular IDEs available for machine learning and AI development based on the number of downloads, number of active users, number of online tutorials and resources available and community size and activity. These factors may change in future –
Jupyter Notebook
Jupyter Notebook is a web-based interactive development environment (IDE) that is popular for machine learning development. Jupyter Notebooks allow you to combine code, text, and images in a single document, which can make it easier to document your machine learning projects. Jupyter Notebook is used in the Python ecosystem. It is a popular tool for data science and machine learning, and it is often used in conjunction with other Python libraries, such as NumPy, Pandas, and Scikit-learn. P.S. Jupiter notebooks come in different flavors from individual cloud platforms e.g. on Vertex AI (Google’s unified AI platform) it is called vertex AI workbench. It is more powerful, feature rich and expensive than Google Colab.
Pros:
- Easy to use and learn
- Combines code, text, and images in a single document
- Good for documenting machine learning projects
- Can be run in a web browser
Cons:
- Not as well-suited for large or complex projects
- Can be difficult to debug code
- Not as well-integrated with version control systems as some other IDEs
PyCharm
PyCharm is a popular IDE for Python development, and it also has a number of features that make it well-suited for machine learning. PyCharm provides code completion, linting, debugging, and a number of other features that can help you write and debug your machine learning code. PyCharm is also used in the Python ecosystem. It is a more powerful IDE than Jupyter Notebook, and it offers a wider range of features. PyCharm is often used by professional Python developers, and it is also a good choice for machine learning development.
Pros:
- Wide range of features for Python development
- Code completion, linting, debugging, and a number of other features
- Well-integrated with the Anaconda distribution of Python
- Community edition is free to use
Cons:
- Can be a bit heavy and resource-intensive
- Not as well-suited for other programming languages as some other IDEs
Google Colab
Google Colab is a cloud-based Jupyter Notebook environment that is free to use. Google Colab is a good option if you want to collaborate on machine learning projects with others, or if you want to access your machine learning projects from anywhere. Google Colab is used in the cloud computing ecosystem. It is a web-based IDE that runs on Google’s servers. Google Colab is a good option for machine learning development, as it allows you to access powerful computing resources without having to install any software on your own computer.
Pros:
- Free to use
- Cloud-based, so you can access your projects from anywhere
- Good for collaboration
- Can run on GPU hardware for faster performance
Cons:
- Not as well-suited for offline work
- Can be difficult to set up
- Not as well-integrated with version control systems as some other IDEs
Spyder
Spyder is a Python IDE that is specifically designed for scientific computing and machine learning. Spyder provides a number of features that are useful for machine learning, such as a graphical debugger, a variable explorer, and a built-in documentation viewer. Spyder is used in the Python ecosystem. It is a scientific Python IDE, and it is often used for data science and machine learning. Spyder offers a number of features that are useful for scientific computing, such as a graphical debugger and a variable explorer.
Pros:
- Specifically designed for scientific computing and machine learning
- Provides a number of features that are useful for machine learning, such as a graphical debugger, a variable explorer, and a built-in documentation viewer
- Well-integrated with the Anaconda distribution of Python
Cons:
- Not as well-suited for other programming languages as some other IDEs
- Can be a bit complex to learn
RStudio
RStudio is an IDE for the R programming language, which is another popular language for machine learning development. RStudio provides a number of features that are useful for machine learning, such as code completion, linting, debugging, and a number of other features. RStudio is used in the R ecosystem. R is a popular programming language for statistical computing, and RStudio is a popular IDE for R development. RStudio offers a number of features that are useful for statistical computing, such as a graphical debugger and a console.
Pros:
- Wide range of features for R development
- Code completion, linting, debugging, and a number of other features
- Well-integrated with the R distribution of Python
- Community edition is free to use
Cons:
- Not as well-suited for other programming languages as some other IDEs
- Can be a bit complex to learn
Jupyter Notebook is the most popular IDE for machine learning development. It is easy to use and learn, and it is a good way to get started with machine learning. PyCharm is another popular IDE for machine learning development. It offers more features and functionality than Jupyter Notebook, but it can be a bit more complex to learn. Google Colab is a cloud-based IDE that is free to use. It is a good option if you want to collaborate on machine learning projects with others, or if you want to access your machine learning projects from anywhere. These IDEs are all open source, which means that they are free to use and modify. They are also actively developed by their respective communities, which means that new features and bug fixes are constantly being added.
Ultimately, the best IDE for you will depend on your specific needs and preferences. If you are new to machine learning, I recommend starting with Jupyter Notebook or Google Colab. These IDEs are easy to use and learn, and they are a good way to get started with machine learning. If you are more experienced with machine learning, you may want to try PyCharm or Spyder. These IDEs offer more features and functionality, but they can be a bit more complex to learn. In addition, these IDEs can be used for other AI development. They are not specifically designed for machine learning, but they can be used for other AI tasks, such as natural language processing and computer vision. For example, Jupyter Notebook can be used to develop and deploy AI chatbots, and PyCharm can be used to develop and deploy AI image classifiers.