
Nathan Marz, who also created Apache storm, came up with term Lambda Architecture (LA). Although there is nothing Greek about it, I think it is called so, primarily because of its shape. It is a data processing architecture designed to handle massive data quantities of data by taking advantage of both batch and stream processing methods. LA is an approach to building stream processing applications on top of map reduce or storm or similar applications. This architecture has become very popular in big data space with companies such as LinkedIn, twitter and Amazon.
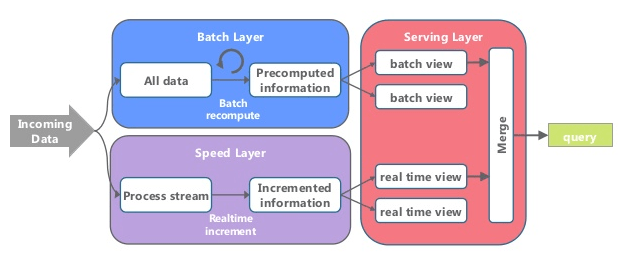
Lambda Architecture pattern solves the problem of speed on Big data and is suited to applications, where there are delays in data collection, and availability through dashboards, requiring data validity for online processing for older data sets to find a behavioral pattern as per users’ needs. One of the basic requirement for LA is to have an immutable data store, which appends the data instead of the following update and delete as part of CRUD operations. But the downside of this immutable data store is that batch processing is not real time. Although the batch processing will improve with time, it is also true that the volume of data grows at the same pace, if not faster. Applications for BI or delivery layer expect to access the data real time, and cannot rely entirely on batch processing to finish up.
The way it works is that an immutable sequence of records is captured and fed into the batch system, and stream processing system in parallel. The transformation logic is applied twice to both processing systems – once in batch and once in stream processing. The result is then stitched together from both the systems at query time to present final answer.
So why there is so much buzz about Lambda Architecture these days. Well…the reason most likely is because of the data space becoming more complex and business expectations of quick data insights raised, there is a need to build low latency processing systems. What we have at our disposal is are scalable high latency batch system that can process historical data and a low latency stream processing system that can process results. By merging these two solutions we can actually build a workable solution.

